
So far, there have been many things to measure of our review process at COLING. Here are a few.
Firstly, it’s interesting to see how many reviewers recommend the authors cite them. We can’t evaluate how appropriate this is, but it happened in 68 out of 2806 reviews (2.4%).
Best paper nominations are quite rare in general. This gives very little signal for the best paper committee to work with. To gain more information, in addition to asking whether a paper warranted further recognition, we asked reviewers to say if a given paper was the best out of those they had reviewed. This worked well for 747 reviewers, but 274 reviewers (26.8%) said no paper they reviewed was the best of their reviewing allocation.
Mean scores and confidence can be broken down by type, as follows.
| Score | Confidence | |
| Computationally-aided linguistic analysis | 2.85 | 3.42 |
| NLP engineering experiment paper | 2.86 | 3.51 |
| Position paper | 2.41 | 3.36 |
| Reproduction paper | 2.92 | 3.54 |
| Resource paper | 2.76 | 3.50 |
| Survey paper | 2.93 | 3.58 |
We can see that reviewers were least confident with position papers, and were both most confident and most pleased with survey papers—though reproduction papers came in a close second in regard to mean score. This fits the general expectation that position papers are hard to evaluate.
The overall distribution of scores follows.
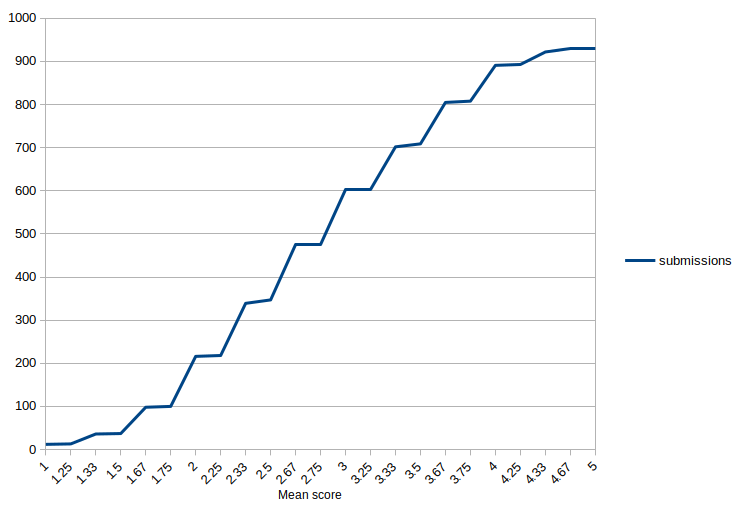
This graph is really hard to read. Can we get a clearer figure?
It seems WordPress automatically resized the image, making it harder to read. The original image is clearer: http://coling2018.org/wp-content/uploads/2018/04/Untitled-1.png
(Thanks for the post, Leon!)
Thanks, Emil. In fact Emily and I co-author all posts and often one of us will start a particular post and the other finish it, but we both appreciate the sentiment!
Ah, WP picked an unfortunate resolution. How about now? It’s not the interactive SVG we’d all hoped for, but I hope it is sufficient for the point.
Whats the graph all about!?
Cumulative distribution of mean overall recommendation; count on y, mean on x.
What’s the graph about? How come more than 900 submissions have a mean score of 5 (only 1000 submissions in total) ?
This is summed. More than 900 submissions have a mean score of 5 *or less*, i.e. all submissions have a score between 1 and 5 🙂
OTOH, you can see that less than 100 have a score of 4 or more.
does it exactly include a score of 4?
If there’s an x-axis mark for it, it’s included.
In this figure, there is an x-axis mark for score 4. In other words, there are about 900 papers have a mean score less than 4 instead of a mean score less or equal to 4 ?
There are about 900 papers with a mean score of 4 or below (less than or equal).
Thank you for providing the interesting information. Is mean score mean of overall recommendation scores by three reviews??
Yes, that’s correct. It’s only a proxy for quality – overall rec. is assessed subjectively for each paper by the ACs later.
Nice statistics. Would be better if you give the detailed numbers of each mean scores.
Thanks!
Detailed how?
For example, how many papers got the score of 4, how many papers got the score of 3.67 . This may give more information than the single graph.
Oh, no, the data is presented as a graph, not a table. The decision boundary is usually fuzzy with some “hinge loss” and so it’s not always worth going into too much detail here – instead, the general shape is shown.
I just want to thank you, Emily, Leon, for all these great initiatives:
– Having this “reproducibility track” is really really great !
– Anonymity at area chairs level is also nice
– “Minimum author responses” to area chairs looks the right way to go – let’s see afterwards if it went well or not 😉
Even this blog post (although not so original 😉 ) live during rush time is so nice
At this pace, I hope next year we’ll have mandatory attached source code to every submission, that would be another nice progress I think 🙂
Thanks a lot !
Thank you!
We don’t want to lock out those working on unreleasable data (e.g. clinical records), so we can’t really enforce this. What we can do so far – and have done – is to only give best paper awards to papers who have already made code/resource already available, and to run a reproducibility track.
So, just to clarify, decisions with regards to the best papers for this year’s conference have been already made?
The acceptance decision process has not started, and best paper selections will be about two months from now.
Thank you! It’s very nice to know that these initiatives are appreciated.
What is the mean score? is it the average over the overall recommendation scores?
Yes, that’s right
It is with confidence or not?
There is only one variable reported, score.
We don’t see reviewer confidence scores in the reviews. Is that intentional?
Yes, that’s intentional.