The utility of the author response part of the conference review process is hotly debated. At COLING 2018, we decided to have the author response be addressed only to the area chairs (and PC co-chairs), and not the reviewers. The purpose of this blog post is to report back on our experience with this model (largely positive, from the PC perspective!) and also to share with the community what we have learned, inhabiting this role, about what makes an effective author response.
For background, here is a description of the decision making process at the PC level. Keep in mind that COLING 2018 received 1017 submissions, of which 880 were still ‘active’ at the point of these decisions. (The difference is a combination of desk rejects and papers withdrawn, the latter mostly in light of acceptance to other venues with earlier notifications.)
Outline of our process
Final accept/reject decisions for COLING 2018 were made as follows:
We asked the ACs for each area to provide a ranking of the papers in their area and to indicate recommendations of accept, maybe accept, maybe reject, or reject. We specifically instructed the ACs to not use the reviewer scores to sort the papers, but rather to come to their own ranking based on their judgment, given the reviews, discussion among reviews, author responses, and (where necessary) reading the papers.
Our role as PCs was to turn those recommendations into decisions. To do so, we first looked at each area’s report and determined which papers had clear recommendations and which were borderline. For the former, we went with the AC recommendations directly. The borderline cases were either papers that the ACs marked as ‘maybe accept’ or ‘maybe reject’, or, for areas that only used ‘accept’ and ‘reject’, the last two ‘accept’ papers and the first two ‘reject’ papers in the ACs’ ranking. This gave us a bit over 200 papers to consider.
We divided the areas into two sets, one for each of us. (We were careful at this point to put the areas containing papers with which one of us had COIs into the other PC’s stack.) Area by area, we looked at the borderline papers, considering the reviews, the reviewer discussion (if any), the author response, comments from the ACs, and sometimes the papers (to clarify particular points; we didn’t read the papers in full). Although the PC role on START allows us to see the authors of all submissions, we worked out ways to look at all the information we needed to do this without seeing the author names (or institutions, etc).
Of the 200 or so papers we looked at, there were 23 for which we wanted to have further discussion. This was done over Skype, despite the 9 hour time difference! These papers were evenly distributed between Emily’s and Leon’s areas, but clustered towards the start of each of our respective stacks; our analysis is that as we worked our way through the process, we each gained a better sense of how to make the decisions and found less uncertainty. (Discussion of COI papers was done with the General Chair, Pierre Isabelle, not the other PC, per our COI policy.)
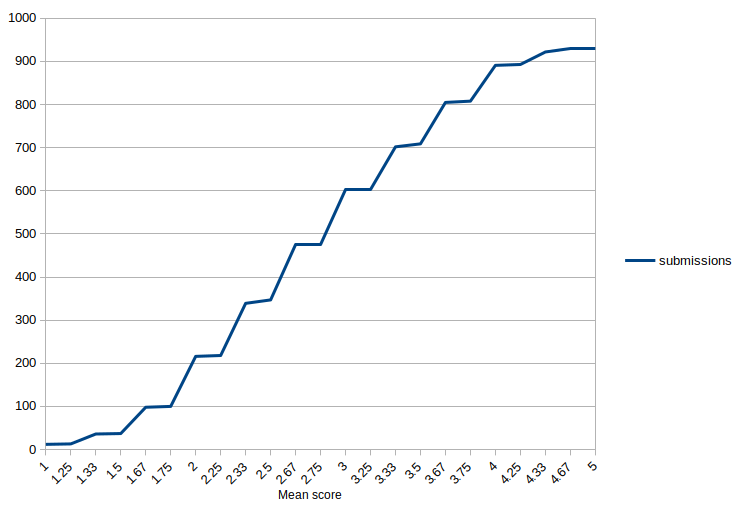
As a final step to verify data entry (to make sure what is entered in START actually matches our intentions), we went through and looked at both the accepted papers with the lowest reviewer scores and the rejected papers with the highest reviewer scores. 98 papers with an average score 3 or higher were rejected. 27 papers with an average score lower than 3 were accepted. (Remember, it’s not just about the numbers!) For each of these, we went back to our notes to check that the right information was entered (it was) and in so doing, we found that, for the majority of the papers which were accepted despite low reviewer scores (and correspondingly harsh reviews), our notes reflected effective author responses. This furthermore is consistent with our subjective sense that the author responses really did make a difference in the case of difficult decisions, that is, the papers we were looking at.
What makes an effective author response?
The effective author responses all had certain characteristics in common. They were written in a tone that was respectful, calm and confident (but not arrogant). They had specific answers to reviewers’ specific questions or specific replies to reviewers’ criticisms. For example, if a reviewer pointed out that a paper failed to discuss important related work, an effective author response would either acknowledge the omission and indicate that it will be addressed in the final version, or clearly state why the indicated paper isn’t in fact relevant. Effective author responses to reviewer questions about points that aren’t clear were short and to the point (and specific). This gave us confidence that the answers would be incorporated in the final version. In many cases, authors related the results of experiments they hadn’t had space for, or ran the analyses during the response period; this is much more effective than an ephemeral promise to add the content. Author responses could also be effective in indicating that reviewers misunderstood key points of the paper or the background into which it fits, but only if they were written in the calm, confident tone mentioned above.
Many effective author responses also expressed gratitude for the reviewers’ feedback. This was nice to see, but it wasn’t a problem when it wasn’t there.
What makes an ineffective author response?
In effective author responses, on the other hand seemed to be written in a place of anger. We understand where authors are coming from when this happens! Reviews, especially negative reviews, can sting. But an author response that comes across as angry, condescending, or combative is not effective at persuading the ACs & PCs that the reviewers have things the wrong way around, nor does it provide good evidence that the paper will be improved for the camera ready version.
Best practices for writing author responses
Here we try to distill our experience of reading the author responses for ~200 papers (not all papers had them, but most did) into some helpful tips.
For conference organizers
We definitely recommend setting up an author response process, but having the author responses go to the ACs (and PCs) only, not the reviewers. Two ways to improve on what we did:
- Clarify the word count constraints better than we did. We asked for no more than 400 words total, but the way START enforced that was no more than 400 words per review (since there were separate author response boxes for each review).
- Don’t make the mistake we made of sending authors who wanted to do a late author response to their ACs … in the very small number of cases where that happened, it compromised anonymity of authors to ACs.
For authors
- Read the reviews and write the angry version. Then set it aside and write a calmer one.
- If you can, show your author response to someone who will read it for you and let you know where it sounds angry/arrogant/petty.
- Try starting with “Thank you for the helpful feedback”—this isn’t necessary, and you can edit it out afterwards for space, but it might help you get off on the right foot regarding tone.
- Don’t play the reviewers off each other (“R1 says this paper is hard to read, but that’s clearly wrong, because R2 said it was easy to follow.”) Rest assured that the ACs will read all of the reviews; they’ll have seen R2’s comments too.
- Similarly, don’t feel obliged to reply to everything in the reviews. General negative comments (e.g. “I found this paper hard to read”) don’t require a response and there probably isn’t a response that would be helpful. Either the paper really is unclear or the reviewer doesn’t have sufficient background / didn’t leave enough time to read the paper carefully. Which scenario this is will likely be evident from the rest of the reviews and the author response.
- Don’t promise the moon and the stars in the final version. It’s hard to accept a borderline paper based on promises alone.
- Do indicate specific answers to key questions, in a way that is obviously easily incorporated in the final version. (And in that case it’s fine to say “We will add clarification along these lines”, or similar.)
- Do concisely demonstrate mastery of the area, if reviewers probe issues you have considered during your research and you have the answers to hand.
- Don’t play games with the word count. We saw two author responses where the authors got around the software’s restriction to 400 words (per box!) by_joining_whole_sentences_with_underscores. This does not make a good impression.
Ultimately, even a calm and confident author response doesn’t necessarily push a paper on the borderline over into accept. Sometimes the paper just isn’t ready and it’s not reasonable to try to fix what needs fixing or add what needs adding for the final version. Nonetheless, we found that the above patterns do make author responses more effective, and so we wanted to share them.